Conventional cloud centralises data processing to deliver efficiencies of scale. But today, everything, from shoes to specks and fridges to vehicles, has become Internet-enabled. The current internet and data centre infrastructure cannot cope. The huge number of devices, volume, and velocity of IoT data create challenges in storage, security, and network management. These challenges threaten the efficacy and integrity of real-time business processes.
Enter fog computing, a new distributed computing model introduced by CISCO. Conventional cloud architecture centralises processing and transports data to distant cloud servers. Fog computing decentralises processing. It brings computing resources near to the edge of the network, rather than transporting data to distant cloud servers. It reduces the computational load on central servers and also the bandwidth requirements.
The OpenFog Consortium defines fog computing as “a system-level horizontal architecture that distributes resources and services of computing, storage, control and networking anywhere along the continuum from Cloud to Things”.
Here are five things you need to know about fog computing for IoT.
1. The fog does not replace the cloud
Fog computing overcomes the technical complexities that limit using the cloud for IoT.
The enormous volumes of IoT and IIoT data, collected by sensors and network edges, have to travel to faraway cloud servers for analytics. This is not always viable as it:
- Draws huge bandwidth, increasing costs.
- Consumes time. The back-and-forth communication between sensors and the cloud negatively affects IoT performance. Also, if the internet is down, the results are not accessible.
- Carries legal implications related to privacy and compliance. In case of a breach, the law of the country where the server is located applies. The law of the place where the data originates does not matter. Different geographies have different legal regulations on data privacy and processing.
With fog computing, data analytics take place at the network edge. Data no longer travels to distant cloud servers, reducing bandwidth costs and latency. Compliance complications also get forestalled.
Consider a patient’s general health data collected in real-time from wearable and blood pressure monitors. Storing such data in the cloud makes the data remain inaccessible if there is no internet connection. There are also question marks on the integrity or privacy of such data. Fog computing performs critical analysis on the data near the device itself, overcoming these issues.
Fog computing is an effective substitute for the cloud, but not a complete replacement. The fog takes care of short-term analysis and ensures the speedy execution of hyper-critical tasks at the source. The cloud still comes into the picture for resource-intensive long-term analytics.
2. Fog Computing is not the same as edge computing
Many analysts consider fog computing as reinventing the wheel as it bears a striking similarity to edge computing.
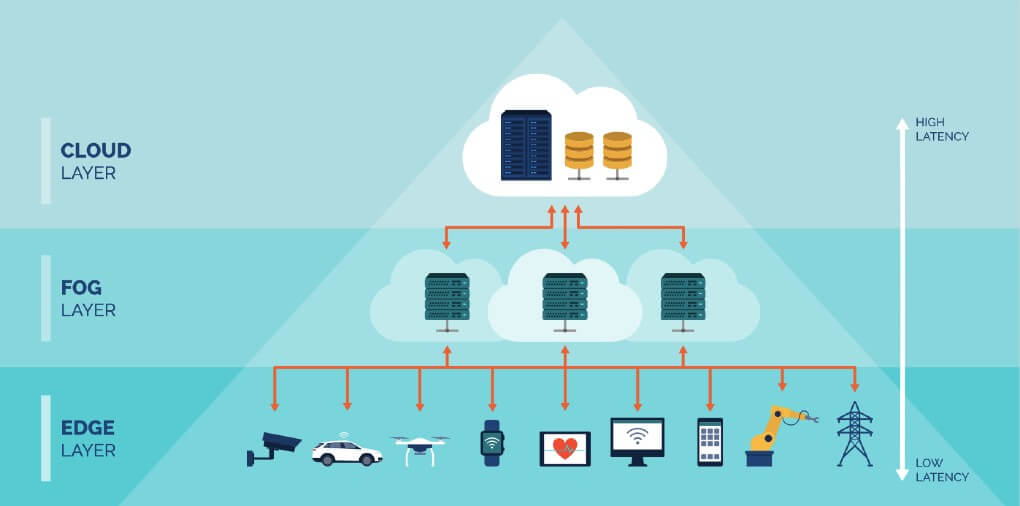
Both the edge and the fog are alternatives to centralized cloud processing. The key difference is the location of the computing resources. Fog computing nodes may reside anywhere in the network, though usually near the edge. It serves as an intermediary between the network and the cloud. Edge computing resources are always at the edge of the network.
Fog nodes find place atop a power pole, a factory floor, in an oil rig, inside a vehicle, or anywhere else. Examples of fog nodes include switches, routers, controllers, embedded servers, or surveillance cameras. The fog architecture features a fog gateway behind which computing nodes reside. Data transmits between network endpoints to the fog gateway, and between the gateways to computing nodes.
In edge computing, the processing sources are at the endpoint or the gateway itself.
The fog scores over the edge in the following ways:
- Fog computing is more scalable than edge computing. The fog architecture features distinct processing sources, with the option of adding as many nodes as needed.
- Fog architecture is more resilient than the edge. Multiple data points feed data into a fog gateway.
- Fog reduces the volume of data sent to the cloud, reducing bandwidth consumption and related costs. Processing data near its source reduces latency as well.
3. Fog success depends on deploying the right resources
Fog computing offers a functional solution to the issues plaguing cloud adoption for IoT.
Conventional cloud employs batch-processing. The fog architecture enables real-time integration of the data with the fog nodes. This fog delivers responses in milliseconds, enabling near-real-time processing of data. Smart edge gateways intelligently process millions of tasks coming from various IoT sensors and monitors. It transmits the summary and exception data to the cloud proper.
One good use case in traffic control. Cities deploy computing resources near the cell tower for real-time analytics of traffic data. The system can respond to changing traffic conditions instantly.
The success of such a setup depends on the resilience of these smart gateways. This rests on:
- Robust connectivity: Real-time processing depends on high-speed connectivity between IoT devices and nodes. The nature of connectivity depends on the setup. For instance, an IoT sensor on a factory floor can connect to the fog resource through a secure and robust wired connection. But an autonomous vehicle or an isolated wind turbine needs 5G, wi-fi or other similar alternative robust connection.
- Running applications on open platforms. Different IoT sensors come from different vendors and have different platforms. The fog integrates these platforms and empowers IoT applications with flexible resources.
- Deploying routers with industrial-strength reliability
4. The Fog has its security issues
The fog compromises the “anywhere” benefits associated with the cloud. Fog computing nodes tie to a physical location and remain susceptible to downtime because of adverse conditions at the location.
Fog reduces the transmission risks to the cloud. But the fog architecture remains susceptible to other security issues, such as IP address spoofing or man in the middle attacks. Devices connecting to fog nodes at multiple gateways complicate the structure. Some of these devices may be vulnerable. Also, cybercriminals could set up a rogue fog node and coax the end-user to connect to it. Once it tricks a user into connecting, it can manipulate the to-and-fro signals to launch attacks.
The flexibility of the fog architecture raises other security issues. Fog computing nodes feature diverse devices from different manufacturers. Enforcing standard security protocols over each such device and node is complex and challenging.
The success of fog computing depends on:
- Placing servers at the right places to deliver maximum services with the lowest latency. Analyse the traffic and the computing demand at each fog node, and deploy adequate resources.
- Enforcing robust authentication protocols to boost security.
- Customising the security policies. The fog addresses security concerns at the network level, making it easier to customise security.
IoT solutions allow people to lock their homes, cook their meals, monitor their health, and even drive them across town. It also supports several hyper-critical business functions. Any downtime for such critical tasks becomes disastrous. Gartner estimates every minute of downtime costs businesses $5600. Successful deployment of IoT depends on the right mix of fog and cloud and optimal use of resources.